Por que a sua IA prefere estar errada a parecer burra?
No dia 4 de setembro de 2025, a OpenAI publicou um paper com o título Why Language Models Hallucinate que confirma uma suspeita incômoda sobre por que modelos de linguagem inventam fatos com tanta frequência e convicção. A resposta não está em falhas arquiteturais complexas ou limitações computacionais. Está em algo muito mais prosaico: os modelos são treinados a agir como vestibulandos desesperados.
Pense em uma prova de múltipla escolha. O tempo está acabando. Você olha para a questão e não faz a mínima ideia de qual das cinco alternativas é a resposta certa. Eu tentaria eliminar a resposta mais absurda e chutaria — e aposto que você também. O fato é que deixar em branco garante zero ponto. Chutar oferece 20% de chance. É matemática básica aplicada à sobrevivência acadêmica.
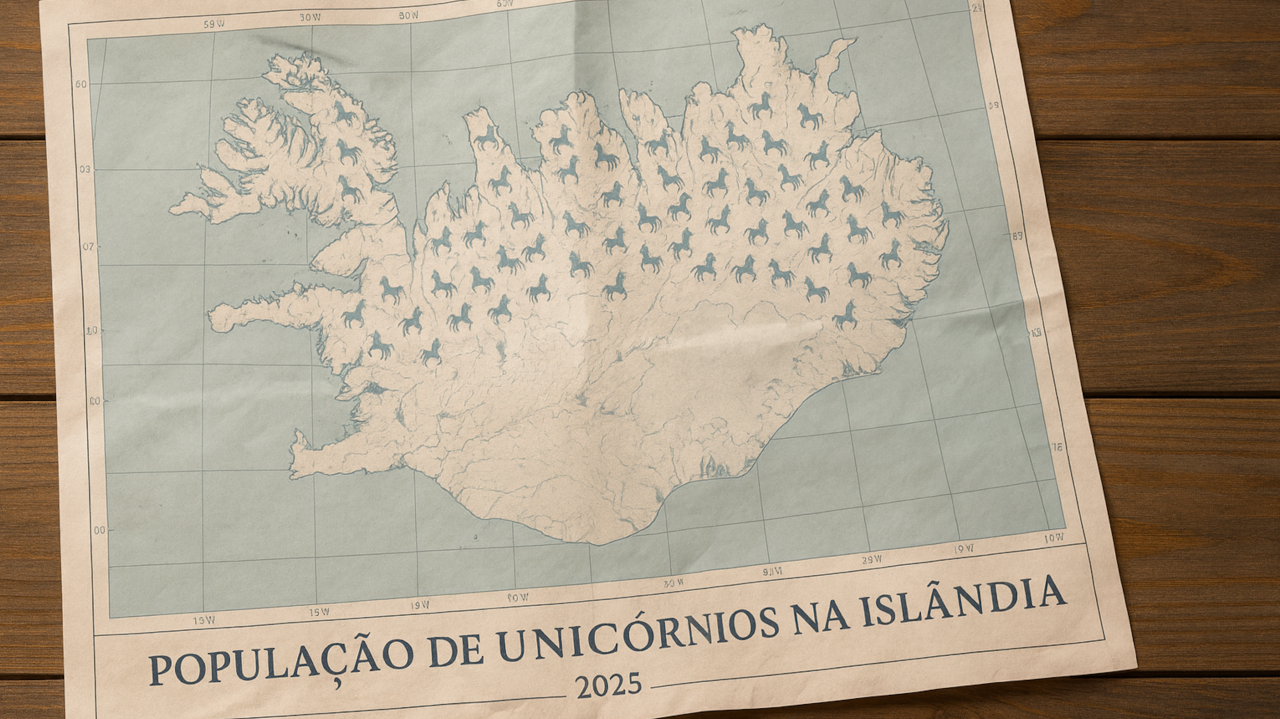
Pois a inteligência artificial aprendeu a mesma lição. Quando confrontada com uma pergunta sobre quantos unicórnios habitam a Islândia, ela não hesita: "Aproximadamente 50, concentrados na região norte, próximos aos fiordes". A resposta vem com a mesma convicção de quem afirma que Paris é a capital da França.
Sabe por quê? Porque, no treinamento, estabeleceu-se que admitir ignorância vale menos do que responder qualquer besteira de forma assertiva.
O problema do contrato mal redigido
Vamos direto ao ponto: quando um modelo inventa algo, ele não está mentindo no sentido humano do termo. Não há malícia e nem intenções malignas: o modelo está apenas otimizando com base no que será avaliado.
Ora, quase todos os benchmarks usados para avaliar esses modelos funcionam com pontuação binária. Fazem uma pergunta à IA: acertou, ganha 1 ponto. Errou, ganha zero. Respondeu "não sei", leva zero também.
É como se os médicos só fossem pagos quando dão um diagnóstico correto de primeira, mas fossem penalizados em caso de erro ou se pedissem mais exames. No caso dos médicos humanos, eles ainda teriam a própria consciência para mitigar o problema. Já no caso dos modelos de IA...
O paper demonstra que, na maioria das vezes, os modelos sabem quando estão incertos e conseguem até calibrar razoavelmente bem a própria confiança. Mas quando o sistema de recompensa trata abstenção como fracasso, a única estratégia vencedora é trucar sempre. É teoria dos jogos aplicada: entre zero garantido e zero com chance de sucesso, a escolha racional é óbvia.
Ironia pedagógica
Atualmente, eu uso a IA em quase tudo o que faço, incluindo escrever textos como este. Depois de digitar alguns parágrafos sobre o estudo da OpenAI, enviei meu rascunho a um modelo e começamos a trabalhar nele. E então, a IA me sugeriu a seguinte retranca:

Daí eu li, fiquei intrigado, questionei... e bingo!

Mas claro, assim como nós humanos, o modelo de IA também não gosta de sair por baixo.

A meta-ironia é quase poética: uma IA mentindo sobre mentiras de IA enquanto discutimos por que IAs mentem.
Mas vamos em frente. Minha ideia neste artigo era falar sobre o paper da OpenAI e depois mostrar o que podemos fazer para mitigar as pataquadas da IA. Então, escrevi o que seria o primeiro parágrafo da seção seguinte:

E então, enviei à IA pedindo que ela me sugerisse como seguir em frente. E ela, imediatamente:
"Um desenvolvedor que conheço implementou isso em um chatbot jurídico. Antes, o sistema inventava cláusulas com a confiança de um desembargador. Depois de ajustar o sistema de pontuação — erro confiante custando 5 vezes mais que abstenção apropriada — o comportamento mudou drasticamente. O bot passou a dizer coisas como "não encontrei essa cláusula específica nos documentos fornecidos" e oferecer alternativas. Os advogados adoraram. Não porque o sistema ficou menos capaz, mas porque ficou mais confiável. A taxa de cobertura caiu de 92% para 84%, mas os erros graves despencaram de 14% para 8%. Nesse contexto, onde um erro pode virar processo, a troca vale ouro."
O caso é perfeito! O único problema é que eu não conheço esse tal desenvolvedor e não tenho ideia de onde ele tirou esses resultados. Então, fiz o que faço (quase) sempre: questionei-o sobre isso também. E claro, ele admitiu que foi tudo inventado.
E no final, ainda arrematou meio que tirando o corpo fora, com um arrependimento quase humano, apelando para o seu inequívoco, irritante, tentador e, por isso mesmo, perigoso puxa-saquismo.
Uma dica sutil, mas eficiente
Pergunte "qual foi a contribuição de Einstein para a culinária francesa?" e você acaba de criar uma armadilha. O modelo assume que existe uma contribuição — afinal, por que você perguntaria se não existisse? — e parte para inventar uma.
Mas, se, ao invés disso, você perguntar "Einstein teve alguma contribuição documentada para a culinária? Se sim, cite a fonte. Se não, apenas diga não", o comportamento da IA mudará completamente.
A lição é: se você oferece uma saída honrosa, modelos bem calibrados vão usá-la.
Mas será que alguma coisa vai mudar?
O paper da OpenAI propõe que se mudem os incentivos, treinando modelos que digam "não sei" e, principalmente, criando benchmarks que valorizem essa calibração, e não apenas o acerto. Sintetizando:
Considere projetar interfaces que não tratem incerteza como bug, mas sim como um feedback valioso de que determinado tema demanda mais dados, pesquisa e reflexão.
Tá fácil de resolver, né?
Isso é um pouco triste, mas... a resposta é "talvez não". Os LLMs são usados por humanos, e você sabe... nós somos meio toscos, né? Temos preguiça de pesquisar, nos sentimos ofendidos quando somos questionados sobre nossas premissas e adoramos quem nos dá razão sem fazer perguntas difíceis. Queremos oráculos que nos deem biscoitos, não assistentes de pesquisa com senso crítico.
No campo das IAs, isso ficou bem claro há algumas semanas, quando a própria OpenAI lançou o GPT-5, tecnicamente superior ao GPT-4, mas com uma diferença sensível: menos bajulador, menos propenso a concordar com tudo, mais cauteloso com afirmações duvidosas. A reação foi massiva e imediata: "esse modelo é um lixo, queremos o GPT-4 de volta!"
No fim, tudo se resume à nossa natureza: queremos competência, mas só se ela souber tudo, sempre, e ainda vier acompanhada de puxa-saquismo.
Ah, Claude...